“우리가 1등” 삼성·SK 신경전 뒤엔 ‘HBM 블랙홀’ 구글·아마존 있다
“삼성전자의 HBM 시장 점유율은 여전히 50% 이상이다. 최근 HBM3 제품은 고객사들로부터 우수하다는 평가를 받고 있다.” (경계현 삼성전자 사장)
“당사는 HBM 시장 초기부터 오랜 기간 동안 경험과 기술경쟁력을 축적해 왔다. 고객들 피드백을 보면 제품 완성도, 양산 품질, 필드 품질을 종합해 당사가 가장 앞서고 있다는 점이 확인되고 있다.”(SK하이닉스 컨퍼런스콜)
국내 반도체 시장이 고대역폭메모리(HBM) 기술 주도권 선점을 놓고 가열되고 있다. 글로벌 메모리 시장에서 삼성전자에 밀려 ‘만년 2위’에 머물러있는 SK하이닉스는 고부가가치 D램인 HBM만큼은 ‘세계 1등’임을 강조하며 고객사 유치에 나섰고, 삼성전자는 경쟁사보다 늦게 HBM 개발에 뛰어들었지만 이미 기술력으로 앞질렀다고 주장한다. 최근 두 기업은 경쟁사에 대한 언급이나 지적은 자제하는 업계 관행을 깨고 자사 HBM 우수성을 알리는 데 혈안이다. 업계에서는 두 회사의 날선 신경전을 두고 구글과 아마존과 같은 대형 고객사 유치를 위한 포석이라는 시각이 나온다.2일 시장조사업체 트렌드포스는 북미와 중국의 클라우드 서버 제공(CSP) 기업들이 인공지능(AI) 서비스 강화에 따라 AI 반도체에 필수인 HBM의 수요가 폭발적으로 늘어날 것이라고 전망했다.
HBM은 여러 개의 D램을 수직으로 쌓아 올려 연결한 반도체로, D램을 많이 쌓을수록 데이터 저장 용량이 크고 처리 속도도 빠르다. 고성능·고용량 장점 덕에 챗GPT와 같은 생성형 AI 등 AI 반도체 시장과 함께 성장하고 있다. 가격은 일반 D램의 6~7배에 달해 삼성전자와 SK하이닉스는 물론 메모리 3위 기업인 미국 마이크론도 HBM 경쟁에 가세했다.
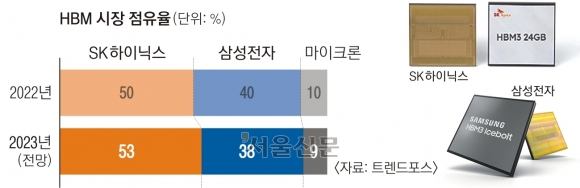
삼성전자 반도체 사업을 총괄하는 경계현 사장은 지난달 자사 임직원 소통행사에서 삼성전자가 HBM 시장에서도 점유율 1위라는 취지로 발언했지만, 트렌드포스는 지난해 말 기준 해당 시장 점유율을 SK하이닉스 50%, 삼성전자 40%, 마이크론 10%로 추정했다. 다만 올해는 SK하이닉스의 시장 점유율은 49.1%로 소폭 낮아지는 반면 삼성전자는 45.6%까지 성장할 것으로 내다봤다. 2024년 전망 점유율은 SK하이닉스 49.6%, 삼성전자 46.2%, 마이크론 4.2% 순이다.
HBM은 제품의 세대가 높아질수록 성능이 크게 개선되는데, 현재 메모리 3사 가운데 SK하이닉스만 가장 최신 세대인 HBM3 양산하고 있다. 챗GPT용 그래픽처리장치(GPU)를 만드는 미국 엔비디아가 SK하이닉스의 HBM3 제품을 쓰고 있다.
삼성전자는 업계 최고 속도와 최저 전력의 HBM3 제품을 개발해 하반기 본격적인 양산을 앞두고 있다. 삼성전자는 지난달 27일 2분기 실적발표 콘퍼런스콜에서 “당사는 HBM 시장의 선두 업체로 HBM2를 주요 고객사에 독점 공급했고, HBM2E도 제품 사업을 원활히 진행 중”이라며 “4세대인 HBM3에서도 업계 최고 수준의 성능과 용량으로 고객과 협의 진행 중”이라고 강조한 바 있다. 삼성전자는 올해 4분기에는 5세대인 HBM3P에 이어 내년부터는 6세대 HBM 양산을 목표로 생산 라인도 대폭 증설할 계획이다.
HBM 개발 경쟁에서 뒤처진 마이크론은 1~3세대 제품을 건너뛰고 곧바로 4세대 제품 개발에 나섰지만, 업계는 마이크론의 HBM 기술력이 검증되지 않았다는 점에서 삼성전자와 SK하이닉스의 경쟁에 주목하고 있다. 특히 AI 서비스 강화를 위해 구글과 아마존 등 대형 클라우드 서버 기업들도 자체 AI칩 개발에 나서면서 삼성전자와 SK하이닉스가 ‘HBM 특수’를 누릴 것으로 보인다. 구글과 아마존은 비용 절감을 위해 엔비디아와 AMD 등 AI칩 전문 기업들로부터 고가의 칩을 구매하는 대신 자체 개발을 진행하고 있지만, 여기에 들어갈 HBM은 여전히 삼성전자와 SK하이닉스 등 메모리 전문 제조사의 제품을 구매해야 한다.
트렌드포스는 클라우드 서버 기업의 AI 고도화에 힘입어 HBM 시장이 올해부터 2025년까지 연평균 45% 급성장할 것이라고 내다봤다.


![고대역폭 메모리(HBM), 미래 고성능 메모리 표준 될까? [고든 정의 TECH+]](https://imgnn.seoul.co.kr/img/upload/2023/08/13/SSI_20230813153736_V.jpg)
![이재용 동선에 삼성 미래 보인다...테슬라·엔비디아 협력강화 [클린룸]](https://img.seoul.co.kr/img/upload/2023/08/09/SSC_20230809154709_V.jpg)




![[고든 정의 TECH+] 이름값 못하는 중급형 그래픽 카드 RTX 4060 Ti…속사정은?](https://imgnn.seoul.co.kr/img/upload/2023/05/25/SSI_20230525093001_V.jpg)
![[고든 정의 TECH+] 432개의 코어를 집적한 ‘메이드 인 유럽’ 프로세서 등장](https://imgnn.seoul.co.kr/img/upload/2023/05/15/SSI_20230515091801_V.jpg)
![[클린룸] 실리콘밸리 일식당서 TSMC ‘큰손’ 마주한 이재용 회장](https://img.seoul.co.kr/img/upload/2023/05/12/SSC_20230512170721_V.jpg)

![[고든 정의 TECH+] 무어의 법칙, 끝나지 않았다? 트랜지스터 집적도 100억 개 돌파한 일반 소비자용 CPU](https://imgnn.seoul.co.kr/img/upload/2023/03/11/SSI_20230311103050_V.jpg)
![[고든 정의 TECH+] 90% 이상 재활용 가능한 그린 PC 등장…컴퓨터의 녹색 바람?](https://imgnn.seoul.co.kr/img/upload/2023/02/27/SSI_20230227100256_V.jpg)







